Titanic Survival
About:
This project / case study is for phase 1 of my 100 days of machine learning code challenge.
This is a homework solution to a section in Machine Learning Classification Bootcamp in Python.
Problem Statement:
Predict Passenger Survival based on feature measurments of the titanic dataset.
Technology used:
Model(s):
Dataset(s):
- The famous Titanic dataset
Libraries:
Resources:
Contact:
If for any reason you would like to contact me please do so at the following:
Import Libraries¶
In [1]:
# import Libraries
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
Import Dataset¶
In [2]:
#import Data into Pandas DataFrame
training_set = pd.read_csv('../datasets/titanic/Train_Titanic.csv')
In [3]:
#Verify Data imported
training_set.head(10)
# training_set.tail(10)
Out[3]:
Explore Dataset¶
In [4]:
survived = training_set[training_set['Survived']==1]
no_survived = training_set[training_set['Survived']==0]
In [5]:
print('Total Passengers = ', len(training_set))
print('Number of Passengers who survived = ', len(survived))
print('Number of Passengers who died = ', len(no_survived))
print('% Survived = ', 1 * len(survived)/len(training_set) * 100)
print('% Died = ', 1 * len(no_survived)/len(training_set) * 100)
In [6]:
# plot Passenger class numbers
sns.countplot(x = 'Pclass', data = training_set)
Out[6]:

In [7]:
# plot Passenger survival by class numbers
sns.countplot(x = 'Pclass', hue = 'Survived', data = training_set)
Out[7]:

In [8]:
# plot Passenger siblings
sns.countplot(x = 'SibSp', data = training_set)
Out[8]:

In [9]:
# plot Passenger survival with siblings
sns.countplot(x = 'SibSp', hue = 'Survived', data = training_set)
Out[9]:

In [10]:
# plot Passengers with Parent / child
sns.countplot(x = 'Parch', data = training_set)
Out[10]:

In [11]:
# plot Passenger survival with Parent / child
sns.countplot(x = 'Parch', hue = 'Survived', data = training_set)
Out[11]:

In [12]:
# plot Passengers embarked
sns.countplot(x = 'Embarked', data = training_set)
Out[12]:

In [13]:
# plot Passenger survival from Embarked
sns.countplot(x = 'Embarked', hue = 'Survived', data = training_set)
Out[13]:

In [14]:
# plot Passengers Sex
sns.countplot(x = 'Sex', data = training_set)
Out[14]:

In [15]:
# plot Passengers Sex Survival
sns.countplot(x = 'Sex', hue = 'Survived', data = training_set)
Out[15]:

In [16]:
# Plot survival by Age
plt.figure(figsize = (40, 30))
sns.countplot(x = 'Age', hue = 'Survived', data = training_set)
Out[16]:

In [17]:
training_set['Age'].hist(bins = 40)
Out[17]:

In [18]:
training_set['Fare'].hist(bins = 40)
Out[18]:

Cleaning Data¶
In [19]:
training_set
Out[19]:
To be cleaned:¶
- Nans
In [20]:
# Find out where NaNs occur
sns.heatmap(training_set.isnull(),
yticklabels = False,
cbar = False,
cmap = 'Blues')
Out[20]:

Columns we don't need:¶
- Cabin
- Name
- Ticket
- Embarked
- Passenger ID
In [21]:
# drop Cabin Data
training_set.drop('Cabin',
axis = 1,
inplace = True)
In [22]:
training_set.head()
Out[22]:
In [23]:
# drop rest of columns not needed:
training_set.drop(['Name',
'Ticket',
'Embarked',
'PassengerId'],
axis = 1,
inplace = True)
In [24]:
training_set.head()
Out[24]:
In [25]:
# Find out where NaNs stil occur
sns.heatmap(training_set.isnull(),
yticklabels = False,
cbar = False,
cmap = 'Blues')
Out[25]:

In [26]:
#plot average ages
plt.figure(figsize = (15,10))
sns.boxplot(x = 'Sex',
y = 'Age',
data = training_set)
Out[26]:

In [27]:
# replace NaN Ages with average ages based on Sex
def fill_age(data):
age = data[0]
sex = data[1]
if pd.isnull(age):
if sex is 'male':
return 29
else:
return 25
else:
return age
In [28]:
training_set['Age'] = training_set[['Age', 'Sex'] ].apply(fill_age, axis = 1)
In [29]:
# Verify NaNs no longer apear
sns.heatmap(training_set.isnull(),
yticklabels = False,
cbar = False,
cmap = 'Blues')
Out[29]:

In [30]:
# see new distibution after replacing NaNs
# May affect prediction results with such big changes
training_set['Age'].hist(bins = 40)
Out[30]:

In [31]:
training_set
Out[31]:
In [32]:
male = pd.get_dummies(training_set['Sex'])
In [33]:
male
Out[33]:
In [34]:
# Drop column because we only need one
male = pd.get_dummies(training_set['Sex'],
drop_first = True)
In [35]:
male
Out[35]:
In [36]:
# Drop Sex Column
training_set.drop(['Sex'], axis = 1, inplace = True)
In [37]:
training_set = pd.concat([training_set, male], axis = 1)
In [38]:
training_set.head()
Out[38]:
Assign Data and Labels¶
In [39]:
X = training_set.drop('Survived', axis = 1).values
In [40]:
X
Out[40]:
In [41]:
y = training_set['Survived'].values
In [42]:
y
Out[42]:
Training the Model¶
In [43]:
# Train Test Split the data
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size = 0.2,
random_state = 10)
In [44]:
# Train Logistic Regression Model
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)
Out[44]:
Model Evaluation¶
In [45]:
y_predict = classifier.predict(X_test)
In [46]:
y_predict
Out[46]:
In [47]:
from sklearn.metrics import confusion_matrix
In [48]:
cm = confusion_matrix(y_test, y_predict)
In [49]:
sns.heatmap(cm, annot = True, fmt = 'd')
Out[49]:

In [50]:
from sklearn.metrics import classification_report
print(classification_report(y_test, y_predict))
In [51]:
# Simple Score output
classifier.score(X_test, y_test)
Out[51]:
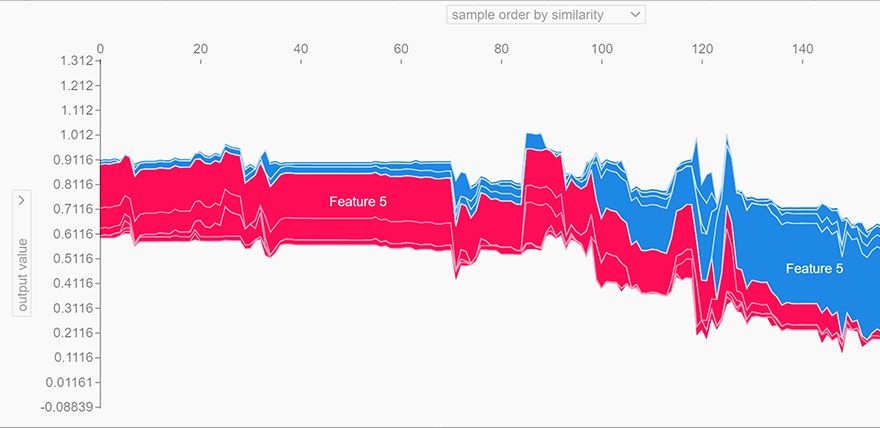
Shap Values¶
In [52]:
import shap
# print the JS visualization code to the notebook
shap.initjs()
# explain all the predictions in the test set
explainer = shap.KernelExplainer(classifier.predict_proba, X_train)
shap_values = explainer.shap_values(X_test)
shap.force_plot(explainer.expected_value[0], shap_values[0], X_test)

Out[52]:
In [53]:
# Feature 5 = Sex
# Feature 0 = Class
# Feature 2 = Had siblings
# Feature 1 = age
# Feature 4 = Fare
# Feature 3 = Parent / child
shap.summary_plot(shap_values)

In [54]:
X_train
Out[54]: